The Evolution of Operations: From DevOps to MLOps and LLMOps
In today’s technology landscape, the pace of innovation is impressive, and with it has emerged a fascinating evolution in operational methodologies. At OpsAnalytics, we have witnessed firsthand how organizations transition from traditional DevOps practices towards more specialized approaches like MLOps and LLMOps, especially as they adopt artificial intelligence and machine learning.
This transition is not merely a matter of terminology, but a fundamental response to new technical challenges. While DevOps focuses on the rapid and reliable delivery of conventional software, MLOps and LLMOps address the unique complexities of AI systems in production.
Understanding the Fundamentals: DevOps as the Foundation
The DevOps approach, which many of our clients have successfully adopted, focuses on shortening development cycles, maintaining quality through continuous integration and delivery (CI/CD), and operating services reliably. At OpsAnalytics, we have implemented DevOps transformations in sectors such as insurance, retail, and manufacturing, observing how some organizations achieve downtime reductions of up to 99.9%.
DevOps’ strength lies in its ability to automate processes, improve collaboration between teams, and foster a culture of continuous improvement. However, when teams begin implementing machine learning systems, they encounter significant limitations in these traditional practices.
The MLOps Revolution: Beyond Code
MLOps represents a specialized extension of DevOps that addresses the particularities of machine learning systems. A crucial point highlighted in the studied material is that “the ML model itself is just a small part of an ML system in production”. The surrounding infrastructure for data, configuration, automation, deployment, and monitoring is much larger and more complex.
Unlike traditional software development, which is a deterministic process, ML development is highly experimental and data-driven. Teams test multiple algorithms, features, and hyperparameters to find what works best. This adds the challenge of tracking experiments, handling stochastic results, and ensuring reproducibility.
In MLOps, versioning of data and models (not just code) becomes critical, something traditional DevOps doesn’t cover by default. Furthermore, ML systems require additional testing: we not only need unit tests for our data preprocessing steps but also need to validate data quality and evaluate trained model performance.
Extended ML Lifecycle
MLOps introduces concepts like continuous training (CT) in addition to CI/CD. This means the system can trigger retraining when new data arrives or when performance degrades, closing the loop between data and deployment. This capability is fundamental because, once deployed, ML models face changing real-world conditions: users may behave differently over time, data can drift, and model performance can deteriorate.
Without proper MLOps, an accurate model can quickly become unreliable or even harmful when serving customers. Lack of proper operations can lead to outdated or incorrect models remaining in production, causing erroneous predictions that harm the business.
The Specialization of LLMOps: Agent Optimization and Prompt Engineering
With the rise of large language models (LLMs), an even more specific specialization has emerged: LLMOps. This discipline focuses on the operations of LLM-based systems, where tools like Opik Agent Optimizer demonstrate the evolution of these practices.
LLMOps addresses unique challenges such as:
- Automatic prompt optimization using specialized algorithms
- Tool and MCP signature management (Model Context Protocol)
- Multi-agent systems with deep observability
- LLM-specific parameters like temperature, top_p, etc.
Modern LLMOps tools offer capabilities such as optimization through MetaPrompt, HRPO (Hierarchical Reflective Prompt Optimizer), evolutionary algorithms, and GEPA, each with specific strengths for different optimization tasks.
Comparative Table: DevOps vs. MLOps vs. LLMOps
| Aspect | DevOps | MLOps | LLMOps |
|---|---|---|---|
| Primary Focus | Rapid and reliable software delivery | Complete ML model lifecycle | LLM system optimization and operation |
| Development Nature | Deterministic | Experimental and data-driven | Prompt and parameter-based |
| Versioned Elements | Code, configuration | Code, data, models, experiments | Prompts, parameters, tools, agents |
| Additional Testing | Unit, integration, functional | Data quality, model performance, bias | Prompt effectiveness, agent behavior |
| Key Automation | CI/CD | CI/CD/CT | Continuous prompt and agent optimization |
| Success Metrics | Delivery time, stability | Model performance, data drift | Response quality, cost per token |
| Critical Infrastructure | Servers, containers, orchestration | Data pipelines, model storage | LLM APIs, response caching systems |
Strategic Implementation for Enterprises
At OpsAnalytics, we recommend a gradual approach to adopting these methodologies:
- Consolidate DevOps foundations first before advancing to MLOps
- Assess current maturity in data management and experimental processes
- Start with specific use cases before scaling horizontally
- Invest in observability and monitoring from the beginning
- Foster collaboration between data science, engineering, and operations teams
For organizations that already have ML implementations in production, the next natural step is to establish automatic retraining mechanisms and data quality monitoring systems. For those experimenting with LLMs, the priority should be establishing processes for systematic prompt optimization and agent behavior evaluation.
Conclusion: A Continuum of Operational Maturity
The evolution from DevOps to MLOps and LLMOps represents a continuum of operational specialization that responds to the technical complexities of increasingly sophisticated systems. What began as a methodology to accelerate traditional software delivery now specializes to address the unique challenges of machine learning and large language models.
At OpsAnalytics, we believe understanding these differences and similarities is crucial for organizations seeking to scale their AI capabilities without losing speed or control. The key lies in recognizing that each transition requires not only new tools but also adjustments in processes, organizational skills, and collaborative culture.
Is your organization considering this operational evolution? In upcoming articles, we will delve deeper into specific implementation strategies for each of these operational domains.
Practical Example: Product Recommendation System
Let me show you how a product recommendation system for an e-commerce platform evolves when implementing each operational approach. This example will allow you to clearly see the practical differences.
Phase 1: DevOps (Traditional System)
Context: Your company needs a basic recommendation system based on predefined business rules.
Python code
# Sistema DevOps tradicional
class BasicRecommendationSystem:
def __init__(self):
self.rules = {
'category_match': True,
'price_range': (10, 100),
'in_stock': True
}
def recommend(self, user_history):
# Lógica determinista basada en reglas
recommendations = self.apply_business_rules(user_history)
return recommendations[:5]Typical DevOps Flow:
- Development: Code with deterministic logic
- Testing: Unit and integration tests (does it return 5 products?)
- CI/CD: Automated pipeline deploys code
- Monitoring: Latency, availability, error logs
- Updates: New release every 2 weeks with rule improvements
Problem encountered: Recommendations are generic, not personalized. Conversion is low because all users see roughly the same items.
Phase 2: MLOps (System with Machine Learning)
Context: You decide to implement an ML model that learns from user behaviors.
Python code
# Sistema MLOps - Mucho más complejo
class MLRecommendationSystem:
def __init__(self):
self.model = None
self.feature_store = FeatureStore()
self.data_pipeline = DataPipeline()
self.model_registry = ModelRegistry()
def train_pipeline(self):
# Pipeline de entrenamiento automatizado
data = self.data_pipeline.collect(user_interactions, product_catalog)
features = self.feature_store.compute_features(data)
self.model = self.train_model(features)
self.evaluate_model() # Validación estadística
self.model_registry.register(self.model, version='v2.1')
def recommend(self, user_id):
# Predicción en tiempo real
user_features = self.feature_store.get_user_features(user_id)
predictions = self.model.predict(user_features)
return self.format_recommendations(predictions)Complete MLOps Flow:
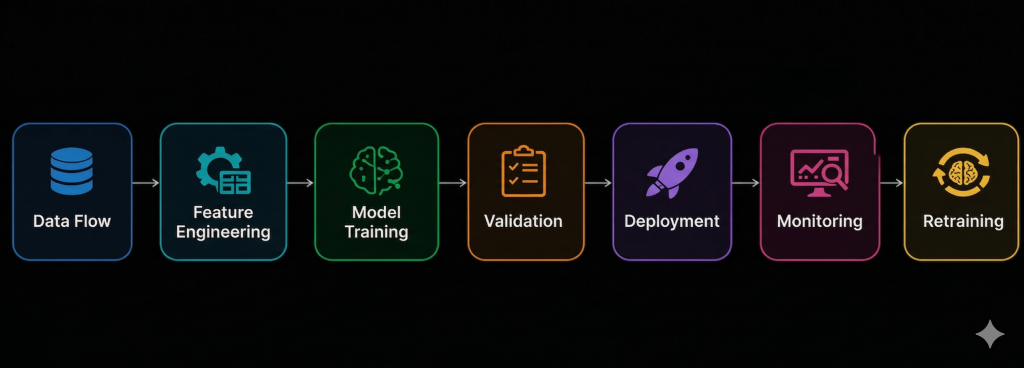

Key Added Components:
- Feature Store: Stores user/product characteristics
- Data Pipeline: Processes data every 24h for retraining
- Model Registry: Model version control
- Monitoring: Tracking data drift and concept drift
- CI/CD/CT: Continuous training when performance drops below 85%
Problem encountered: The model works well initially, but then:
- Users ask specific things (“gift for a 5-year-old boy”)
- Natural language searches aren’t interpreted well
- Recommendations don’t consider conversational context
Phase 3: LLMOps (System with Language Models)
Context: You implement a conversational agent that understands natural language and generates contextual recommendations.
Python code
# Sistema LLMOps con agente inteligente
class LLMRecommendationAgent:
def __init__(self):
self.llm_client = LLMClient(model="gpt-4")
self.tools = [
ProductSearchTool(),
UserProfileTool(),
ConversationHistoryTool(),
ReviewAnalyzerTool()
]
self.prompt_optimizer = OpikAgentOptimizer()
self.evaluator = RecommendationEvaluator()
def optimize_prompt(self):
# Optimización automática del prompt del sistema
optimized_prompt = self.prompt_optimizer.optimize(
initial_prompt="Eres un asistente de recomendaciones...",
dataset=conversation_examples,
metrics=[relevance_score, conversion_likelihood]
)
return optimized_prompt
def recommend(self, user_query, conversation_history):
# Agente con razonamiento y herramientas
context = self.build_context(user_query, conversation_history)
response = self.llm_client.generate(
system_prompt=self.optimized_prompt, # Prompt optimizado
user_message=user_query,
tools=self.tools,
temperature=0.3, # Parámetro optimizado
max_tokens=500
)
# Log para observabilidad
self.log_trace({
'query': user_query,
'tools_used': response.tools_called,
'token_usage': response.usage,
'confidence': response.confidence_score
})
return response.recommendations
Characteristic LLMOps Flow
Unique LLMOps Components:
- Prompt Optimization: Automatic improvement of model instructions
- Tool Calling: The LLM decides which tools to use (search products, check profile)
- Parameter Tuning: Adjusting temperature, top_p to balance creativity/consistency
- Trace Logging: Detailed agent reasoning logging
- Multi-turn Context: Maintains conversational context
- Cost Optimization: Balance between response quality and tokens used
Practical Comparison of the Three Approaches
| Scenario | DevOps | MLOps | LLMOps |
|---|---|---|---|
| User asks: “I need a gift for my 7-year-old niece who likes art” | Recommends products in “toys + art” category (predefined rules) | Recommends products bought by similar users (user clusters) | Conversation: “Do you prefer drawing materials, craft kits, or creative games? My 6-year-old niece loves paint-by-number kits” |
| System Update | Manual deploy every 2 weeks with new rules | Automated retraining pipeline every 24h | Real-time prompt optimization based on successful conversations |
| Typical technical problem | Server down, error 500 | Data drift: new products lack embeddings | Prompt injection, inconsistent responses |
| Key Metrics | 99.9% availability, response time <200ms | 85% precision, 70% coverage, ROC-AUC 0.89 | User satisfaction 4.5/5, conversion rate 12%, cost per conversation $0.03 |
| Scalability | More servers, load balancing | More training clusters, distributed feature stores | Token optimization, response caching, more efficient models |
| Team Required | DevOps Engineer, Backend Developer | Data Engineer, ML Engineer, Data Scientist | Prompt Engineer, LLM Ops Engineer, Conversation Designer |
Lessons Learned from the Example
- Increasing complexity but added value: Each transition adds complexity but also more sophisticated capabilities.
- Natural evolution: Many companies start with DevOps, then implement MLOps for specific cases, and finally explore LLMOps for conversational interfaces.
- Different costs:
- DevOps: infrastructure cost
- MLOps: data + training cost
- LLMOps: LLM token cost + optimization
- Implementation time:
- DevOps: 2-4 semanas
- MLOps: 2-3 meses (con pipelines robustos)
- LLMOps: 1-2 meses pero con iteración continua
Recommendation for Gradual Implementation
At OpsAnalytics, we suggest this path:
- Week 1-4: Implement basic DevOps system with simple rules
- Month 2-3: Add a simple ML model (light MLOps) for basic personalization
- Month 4-6: Implement LLM for conversational search while refining the MLOps pipeline
- Month 6+: Hybrid system where each approach handles what it does best
What’s the biggest mindset shift? Moving from thinking about “code that executes” (DevOps) to “models that learn” (MLOps) and finally to “agents that reason” (LLMOps).
Would you like me to delve deeper into any specific aspect of this practical implementation?
Practical Case: Premium Calculation System in an Insurance Company
Let me show you how an insurance company evolves its premium calculation and risk assessment system by implementing DevOps, MLOps, and LLMOps. This realistic example will show you the concrete operational differences.
Insurance Company Context
Seguros Futuro S.A. has:
- 500,000 auto insurance clients
- 50 field agents
- Web portal and mobile app
- Needs to calculate premiums and evaluate claims
Phase 1: DevOps (Traditional Premium Calculation System)
Initial problem: Manual premium calculation with static Excel tables, slow processes prone to errors.
Python code
# Sistema DevOps - Lógica determinista basada en reglas
class TraditionalInsuranceCalculator:
def __init__(self):
self.base_rates = {
'auto': {'base': 500, 'per_age': 10},
'home': {'base': 300, 'per_value': 0.001},
'health': {'base': 400, 'per_age': 15}
}
self.discount_rules = {
'good_driver': 0.15,
'multiple_policies': 0.10,
'loyalty_5_years': 0.05
}
def calculate_premium(self, customer_data):
# Cálculo determinista basado en reglas fijas
base = self.base_rates[customer_data['policy_type']]['base']
age_factor = customer_data['age'] * self.base_rates[customer_data['policy_type']].get('per_age', 0)
premium = base + age_factor
# Aplicar descuentos
for discount_type in customer_data.get('discounts', []):
premium *= (1 - self.discount_rules.get(discount_type, 0))
return round(premium, 2)
DevOps Operational Flow:
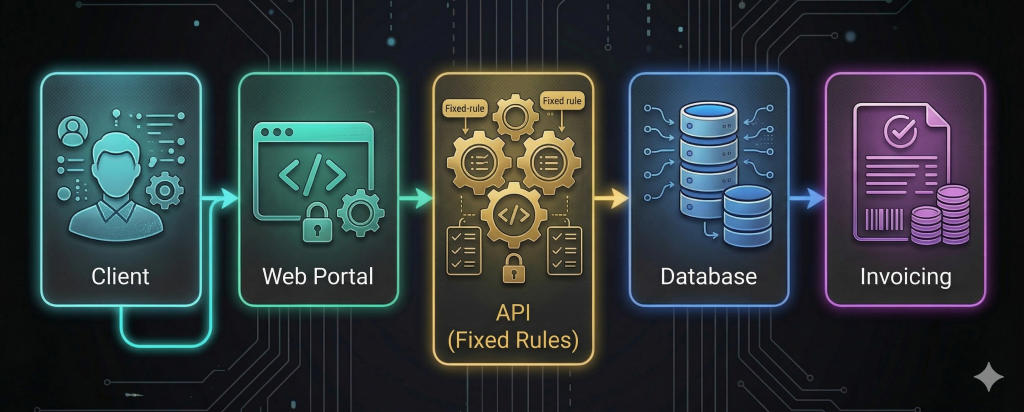
Pipeline CI/CD Pipeline:
yaml
# .github/workflows/deploy.yml
name: Deploy Insurance Calculator
on:
push:
branches: [main]
jobs:
test-and-deploy:
runs-on: ubuntu-latest
steps:
- name: Run Unit Tests
run: python -m pytest test_calculator.py
- name: Deploy to Staging
run: kubectl apply -f k8s/staging/
- name: Integration Tests
run: ./run_integration_tests.sh
- name: Deploy to Production
if: success()
run: kubectl apply -f k8s/production/
Problems encountered:
- Uncompetitive premiums: Competitors with ML have more accurate pricing
- Undetected fraud: Suspicious claim patterns go unnoticed
- Response time: 48 hours to evaluate complex claims
- Slow updates: Changing tables requires manual deployment
Phase 2: MLOps (Predictive Risk System)
Transformatión: They implement ML models to:
- Predict claim probability
- Detect potential fraud
- Personalize premiums individually
Python code
# Sistema MLOps - Pipeline completo de ML
class MLRiskAssessmentSystem:
def __init__(self):
self.feature_pipeline = FeaturePipeline()
self.model_trainer = ModelTrainer()
self.model_serving = ModelServing()
self.monitoring = ModelMonitoring()
def retraining_pipeline(self):
"""Pipeline automatizado de reentrenamiento"""
# 1. Recolectar nuevos datos
new_claims = self.collect_recent_claims(last_90_days=True)
new_customers = self.collect_new_customer_data()
# 2. Ingeniería de características
features = self.feature_pipeline.transform({
'demographics': new_customers,
'claims_history': new_claims,
'external_data': weather_data, traffic_data
})
# 3. Entrenar modelos
risk_model = self.model_trainer.train(
features=features,
target='claim_probability',
algorithm='xgboost',
test_size=0.2
)
fraud_model = self.model_trainer.train(
features=features,
target='is_fraudulent',
algorithm='isolation_forest'
)
# 4. Validación rigurosa
if self.validate_models(risk_model, fraud_model):
# 5. Despliegue canario
self.model_serving.deploy_canary(
new_models={'risk': risk_model, 'fraud': fraud_model},
traffic_percentage=10
)
# 6. Monitoreo continuo
self.monitoring.setup_alerts(
metrics=['accuracy_drop', 'data_drift', 'concept_drift'],
thresholds={'accuracy_drop': 0.05}
)
Complete MLOps Architecture:
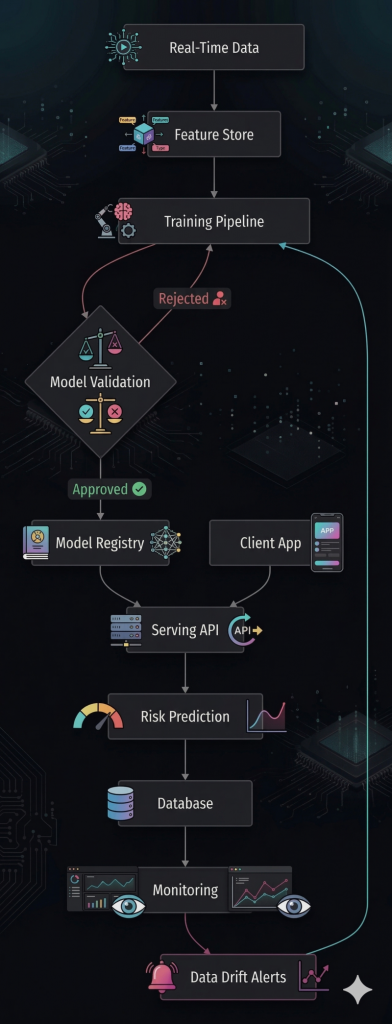
Benefits obtained with MLOps:
- More accurate premiums: 15% reduction in under-pricing losses
- Fraud detection: Identify 40% more frauds
- Automation: Claim evaluation in 2 hours vs. 48 hours
- Updates: Automatic weekly retraining
New problems:
- Complex claims: Some cases require natural language interpretation
- Customer service: Agents can’t explain model decisions
- Documentation: Processing expert reports takes a lot of time
- Regulation: Need explainability for supervisors
Phase 3: LLMOps (Intelligent Claims Assistant)
Innovation: They implement an LLM agent that:
- Reads and summarizes expert reports
- Explains decisions to clients
- Assists agents in real-time
- Generates regulatory documentation
Python code
# Sistema LLMOps con agente especializado
class InsuranceLLMAgent:
def __init__(self):
self.llm = LLMClient(model="claude-3-opus")
self.tools = {
'policy_lookup': PolicyDatabaseTool(),
'claim_analyzer': ClaimAnalysisTool(),
'fraud_detector': FraudDetectionTool(),
'document_processor': DocumentProcessingTool(),
'regulation_checker': ComplianceTool()
}
self.prompt_manager = PromptManager()
self.evaluator = AgentEvaluator()
def optimize_insurance_prompts(self):
"""Optimización específica para seguros"""
optimized_prompt = self.prompt_manager.optimize(
base_prompt="""Eres un especialista en seguros con 20 años de experiencia.
Objetivo: {objective}
Regulaciones aplicables: {regulations}
Contexto del caso: {context}""",
optimization_algorithm="HRPO", # Hierarchical Reflective Prompt Optimizer
evaluation_metrics=[
'accuracy_explanation', # ¿La explicación es técnicamente correcta?
'regulatory_compliance', # ¿Cumple normativas?
'customer_clarity', # ¿El cliente lo entendería?
'processing_speed' # ¿Resuelve en tiempo adecuado?
],
training_data=self.load_insurance_cases(n=1000)
)
return optimized_prompt
def process_claim(self, claim_id, customer_query=None):
"""Procesa un siniestro completo"""
# 1. Recopilar contexto
context = self.build_claim_context(claim_id)
# 2. Ejecutar agente con herramientas
result = self.llm.run_agent(
system_prompt=self.optimized_prompt,
user_query=customer_query or "Procesar este siniestro",
available_tools=self.tools,
tool_selection_strategy="dynamic", # El LLM decide qué herramientas usar
max_processing_time="5m"
)
# 3. Logging detallado para auditoría
self.log_audit_trail({
'claim_id': claim_id,
'llm_reasoning': result.chain_of_thought,
'tools_used': result.tool_calls,
'confidence_scores': result.confidence,
'regulatory_checks': result.compliance_checks
})
# 4. Evaluación continua del agente
self.evaluator.log_interaction(
claim_id=claim_id,
agent_response=result,
human_feedback=None, # Se recibe después
auto_metrics=self.calculate_auto_metrics(result)
)
return result
LLMOps Flow for Claim Processing:
Claim Reported
↓
[LLM Agent Analyzes]
├──► Reads expert report (DocumentProcessingTool)
├──► Checks policy (PolicyDatabaseTool)
├──► Verifies fraud (FraudDetectionTool)
├──► Reviews regulations (ComplianceTool)
↓
[Generates Resolution]
├──► Decision: Approve/Reject/Investigate
├──► Compensation calculation
├──► Explanation for client
├──► Regulatory documentation
↓
[Continuous Optimization]
├──► Human agent feedback → Prompt adjustment
├──► Difficult cases → New training data
├──► Regulation updates → Prompt update
Concrete Comparison in the Insurance Company
| Use Case | DevOps | MLOps | LLMOps |
|---|---|---|---|
| Client reports accident | Web form → Manual processing in 3 days | System classifies urgency → Automatically routes in 2 hours | Conversational agent: “I understand your accident. Do you need a tow truck? I’ve already located approved nearby workshops” |
| Damage Assessment | Agent visits → Photos → Manual estimate | CV model analyzes photos → Estimates cost with 85% accuracy | LLM reads expert report + analyzes photos → Explains: “Damage to panel B requires replacement because…” |
| Fraud Detection | Simple rules: multiple claims in short time | Anomaly detection model identifies subtle patterns in 50+ variables | LLM analyzes claim narrative: “The description doesn’t match the photos because…” |
| Premium Calculation at Renewal | Fixed 5% annual increase | Predictive model adjusts according to updated individual risk | Agent explains: “Your premium increases 3% due to increased accidents in your area, but we give you 2% discount for good history” |
| Regulatory Compliance | Manual annual checklist | Automatic monitoring of dataset changes | LLM generates regulatory report + explains each decision in natural language |
| Claim Processing Time | 5-10 business days | 24-48 hours | 2-4 hours for standard cases |
| Operational Cost | $50 per claim (labor) | $15 per claim (ML infrastructure) | $3 per claim (token cost + optimization) |
Quantified Transformation Results
| Metric | DevOps | MLOps | LLMOps | Improvement |
|---|---|---|---|---|
| Claim processing time | 7.2 days | 1.5 days | 0.3 days | 24x faster |
| Compensation calculation | 70% | 89% | 94% | +24 points |
| Fraud detected | 15% | 45% | 68% | +53 points |
| Customer satisfaction | 3.2/5 | 4.1/5 | 4.7/5 | +47% |
| Operational cost/claim | $50 | $15 | $8 | -84% |
| Regulatory compliance | 82% | 91% | 98% | +16 points |
| Case capacity/day | 100 | 450 | 1,200 | 12x more capacity |
Implementation Roadmap for Insurance Companies
Phase 1: DevOps (Month 1-3)
yaml
objetivo: "Automatizar procesos manuales"
acciones:
- Dockerizar aplicaciones existentes
- Implementar CI/CD para sistemas de facturación
- Crear APIs para agentes externos
- Monitoreo básico (uptime, errores)
herramientas: Jenkins, Kubernetes, PrometheusPhase 2: MLOps (Month 4-9)
yaml
objetivo: "Predecir riesgos y optimizar precios"
acciones:
- Feature store para datos de clientes
- Pipeline entrenamiento modelos de riesgo
- Sistema detección fraudes en tiempo real
- Monitoreo data drift en variables clave
herramientas: MLflow, Feast, Evidently AIPhase 3: LLMOps (Month 10-15)
yaml
objetivo: "Experiencia conversacional y automatización compleja"
acciones:
- Agente LLM para procesamiento siniestros
- Optimización prompts específicos seguros
- Sistema explicabilidad decisiones para reguladores
- Integración herramientas existentes con LLM
herramientas: Opik, LangChain, LlamaIndexKey Lessons for the Insurance Sector
- Start simple: Don’t attempt LLMOps without solid DevOps foundations
- Data first: Data quality is critical for MLOps and LLMOps
- Regulation: In insurance, explainability is not optional
- Gradual transition: Many systems can coexist during migration
- Clear ROI: In insurance, every improvement in fraud detection has a direct impact on results
Key question for your insurance company: What stage are you currently in and what would be the most valuable next step?
Leave a Reply