De Jupyter a Producción: Dominando MLOps con MLflow y Databricks

La Promesa y el Desafío de la Inteligencia Artificial Empresarial
La inteligencia artificial ha madurado. Ha pasado de ser una inversión experimental a un activo estratégico que define la competitividad. Sin embargo, la mayoría de las organizaciones descubren que el verdadero desafío no está en crear un modelo preciso, sino en transformarlo en un servicio confiable, escalable y auditable. El camino desde el entorno de experimentación ese notebook de Jupyter donde todo funciona hasta un sistema productivo integrado es complejo y está lleno de riesgos operativos.
Cuando los modelos se gestionan de forma artesanal, las consecuencias son predecibles: incapacidad para reproducir resultados, falta de trazabilidad entre versiones, despliegues frágiles y, en última instancia, una erosión de la confianza en la inversión en IA. Aquí es donde la disciplina de MLOps (Machine Learning Operations) se convierte en un requisito ineludible.
Este artículo proporciona una guía estructurada sobre los fundamentos de MLOps, basada en el ecosistema de referencia actual: MLflow como plataforma de gestión del ciclo de vida del machine learning y Databricks como el entorno empresarial que lo escala. Exploraremos cómo estas herramientas abordan los desafíos centrales de trazabilidad, reproducibilidad y gobierno, y cómo su implementación sienta las bases para una operación de IA madura.
El Problema Estructural: Más Allá del Notebook

El desarrollo de software tradicional es determinista. Una función, dados los mismos argumentos, produce siempre el mismo resultado. El machine learning, por el contrario, es inherentemente probabilístico. El mismo código y los mismos datos pueden generar modelos distintos. A esto se suma una cultura de experimentación intensiva probar decenas de combinaciones de hiperparámetros, arquitecturas y conjuntos de datos que, sin la disciplina adecuada, genera un caos operativo.
Para cualquier empresa que aspire a escalar sus iniciativas de IA, estas preguntas deben tener respuestas inmediatas e inequívocas:
- ¿Qué versión exacta de los datos y del código produjo este modelo?
- ¿Cómo se comparan sistemáticamente los resultados de distintos experimentos?
- ¿Es posible auditar y reproducir un modelo generado hace seis meses con total fidelidad?
- ¿Cómo se gobierna el ciclo de vida completo de un modelo: desarrollo, validación, despliegue, monitoreo y eventual retiro?
Responder a esto requiere una plataforma, no una colección de scripts.
MLflow: La Columna Vertebral de sus Operaciones de ML
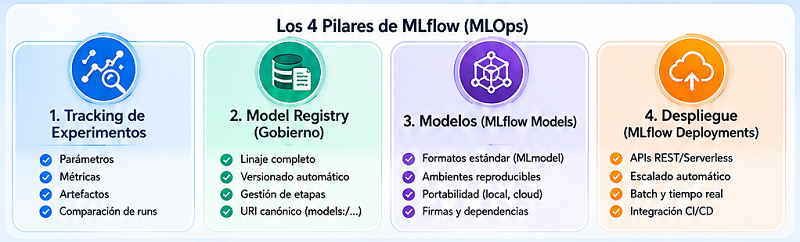
MLflow es una plataforma de código abierto que ha emergido como el estándar de facto para la gestión del ciclo de vida del machine learning. Su diseño modular aborda los cuatro pilares de MLOps:
1. Seguimiento de Experimentos (MLflow Tracking)
El tracking systemático es el primer paso hacia la madurez operativa. Cada ejecución de entrenamiento se registra como un «run» que captura de manera inmutable:
- Parámetros: Las variables de entrada del proceso (tasa de aprendizaje, profundidad máxima, etc.).
- Métricas: Los indicadores cuantitativos de rendimiento (exactitud, precisión, pérdida).
- Artefactos: Los productos generados (el modelo serializado, gráficas de diagnóstico, muestras de datos transformados).
Arquitectónicamente, MLflow separa de forma elegante el almacenamiento de metadatos (el Backend Store, típicamente una base de datos SQL) del almacenamiento de artefactos pesados (el Artifact Store, como AWS S3 o Azure Blob Storage). Esta separación es fundamental para la escalabilidad y permite que equipos distribuidos compartan un servidor central de tracking sin saturarlo con archivos binarios.
2. El Model Registry: Gobierno y Linaje
Entrenar modelos es solo el comienzo. La gobernanza efectiva exige un catálogo centralizado que ofrezca:
- Linaje completo: Trazabilidad inequívoca desde un modelo en producción hasta el experimento, el conjunto de datos y el commit de código que lo originaron.
- Versionado automático: Cada iteración registrada genera una nueva versión, creando un historial inalterable.
- Gestión de etapas: Los modelos transitan por un flujo definido (Staging, Production, Archived), o utilizan alias como «champion» y «challenger» para implementaciones de prueba A/B.
El concepto de Model URI (models:/<nombre>/<versión-o-etapa>) es particularmente poderoso, ya que desacopla el despliegue del modelo de su ubicación física, habilitando pipelines de CI/CD limpios y reproducibles.
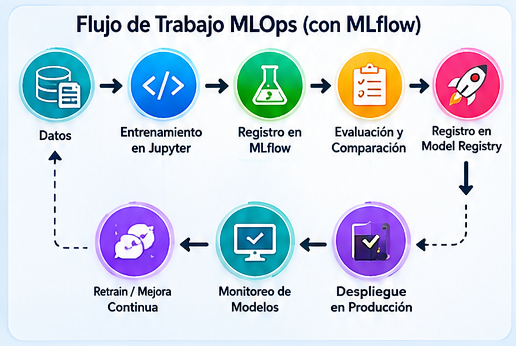
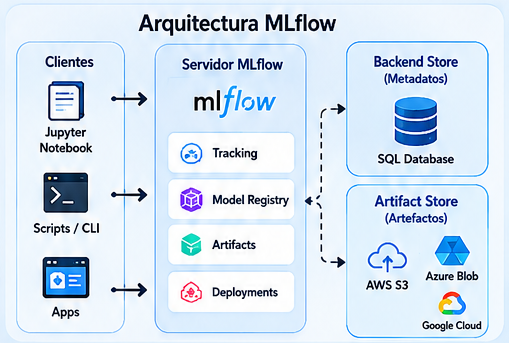
Implementación Técnica: De la Teoría a la Práctica
A continuación, se presentan los patrones de implementación esenciales, extraídos de un flujo de trabajo real con MLflow.
Configuración del Entorno y Servidor de Tracking
El primer principio es el aislamiento. Un entorno virtual por proyecto es la base de la reproducibilidad:
bash
python3.9 -m venv mlflow-env
source mlflow-env/bin/activate
pip install mlflow scikit-learn pandas matplotlibEl servidor de tracking se inicia localmente para desarrollo, pero en producción se configura con backends y artifact stores remotos:
bash
mlflow ui --host 0.0.0.0 --port 5000Registro Estructurado de Experimentos


El siguiente patrón muestra un registro completo de una ejecución, incluyendo parámetros, métricas y el modelo resultante:
python
import mlflow
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
mlflow.set_experiment("Experimento_Iris")
with mlflow.start_run(run_name="RandomForest_Base"):
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(
iris.data, iris.target, test_size=0.2, random_state=42
)
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=42)
model.fit(X_train, y_train)
# Registro de parámetros
mlflow.log_param("n_estimators", 100)
mlflow.log_param("max_depth", 5)
# Registro de métricas
predictions = model.predict(X_test)
mlflow.log_metric("accuracy", accuracy_score(y_test, predictions))
# Registro del modelo como artefacto versionado
mlflow.sklearn.log_model(model, "random_forest_model")
Registro Avanzado: Visualizaciones y Datos
MLflow permite registrar artefactos que van más allá de números: gráficas de pérdida, matrices de confusión y muestras de datos transformados que enriquecen la trazabilidad y facilitan la depuración.
python
import matplotlib.pyplot as plt
# Registrar una gráfica de diagnóstico
plt.figure()
plt.plot(epochs, loss, marker='o')
plt.savefig("training_loss.png")
mlflow.log_artifact("training_loss.png")
plt.close()Automatización con Auto-logging
Para frameworks soportados como scikit-learn, una sola línea habilita el registro automático de parámetros, métricas y modelos, reduciendo el código boilerplate y el riesgo de omisiones humanas:
python
mlflow.sklearn.autolog()El Model Registry en Acción
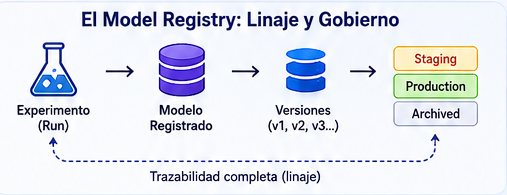
Una vez que un modelo candidato ha sido identificado, se registra formalmente:
python
mlflow.register_model(f"runs:/{run_id}/random_forest_model", "ClasificadorIris")Y se consume en cualquier entorno mediante su URI canónico:
python
modelo_produccion = mlflow.pyfunc.load_model("models:/ClasificadorIris/production")
predicciones = modelo_produccion.predict(datos_nuevos)Este patrón es la clave para integrar el despliegue de modelos en pipelines de integración y entrega continua (CI/CD).
El Salto Empresarial: MLflow sobre Databricks
Si MLflow proporciona el motor, Databricks ofrece la plataforma empresarial que lo integra en un ecosistema gobernado y colaborativo.
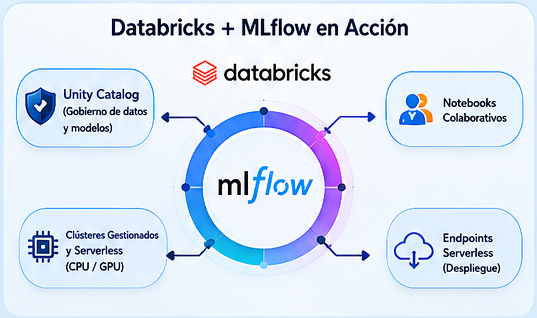
- Colaboración Sin Fricción: Experimentos, notebooks y modelos residen en un espacio de trabajo unificado. El Unity Catalog proporciona un gobierno de datos centralizado con control de acceso granular basado en identidad, aplicable tanto a datos como a modelos.
- Cómputo Gestionado y Serverless: La gestión de infraestructura se abstrae completamente. Clústeres con o sin GPU se aprovisionan bajo demanda, optimizando costos y eliminando la carga operativa del equipo.
- Seguimiento Automatizado: La integración nativa con MLflow significa que el tracking se activa de forma transparente al entrenar en notebooks de Databricks.
- Runs Anidados: Para experimentos complejos como búsqueda de hiperparámetros, los «nested runs» permiten una organización jerárquica, agrupando múltiples ejecuciones hijas bajo un run padre.
Caso Avanzado: Desplegando Modelos de Hugging Face con PyFunc Personalizado
La flexibilidad de MLflow se manifiesta plenamente al abordar modelos no tabulares. Considere el despliegue de un modelo Transformer para análisis de sentimiento. El patrón consiste en encapsular el modelo en una clase Python que hereda de mlflow.pyfunc.PythonModel:
python
class TransformerModel(mlflow.pyfunc.PythonModel):
def load_context(self, context):
self.tokenizer = AutoTokenizer.from_pretrained(self.model_name)
self.model = AutoModelForSequenceClassification.from_pretrained(self.model_name)
def predict(self, context, model_input):
textos = model_input.iloc[:, 0].tolist()
inputs = self.tokenizer(textos, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
outputs = self.model(**inputs)
return pd.DataFrame(torch.softmax(outputs.logits, dim=-1).numpy())Este modelo personalizado se empaqueta con su entorno de dependencias y se registra en el Unity Catalog, listo para ser servido a través de un endpoint REST serverless. Temas críticos como la latencia de «cold start» y el escalado horizontal son gestionados por la plataforma.
Conclusión

Adoptar MLOps no es un evento, sino una evolución progresiva. Desde el tracking local de experimentos hasta el gobierno empresarial de modelos en producción, las herramientas y principios presentados constituyen la base de una operación de IA robusta.
En OpsAnalytics, comprendemos que este camino presenta desafíos técnicos y organizacionales. Nuestra experiencia en DevOps y plataformas de datos nos posiciona para guiar a las organizaciones en la construcción de la infraestructura, los procesos y la cultura necesarios para que sus modelos no solo sean precisos, sino también confiables, escalables y gobernables.
¿Está tu organización preparada para profesionalizar sus operaciones de machine learning? Contáctenos y descubra cómo podemos ayudarle a construir el puente entre la experimentación y el valor de negocio tangible.

Deja una respuesta