From Jupyter to Production: Mastering MLOps with MLflow and Databricks

The Promise and Challenge of Enterprise AI
Artificial intelligence has matured. It has evolved from experimental investment to a strategic asset that defines competitiveness. Yet most organizations discover that the real challenge is not building an accurate modelit is turning that model into a reliable, scalable, and auditable service. The path from the experimentation environment (where everything works in a Jupyter notebook) to an integrated production system is complex and full of operational risks.
When models are managed manually, the consequences are predictable: inability to reproduce results, lack of traceability across versions, fragile deployments, and ultimately, erosion of trust in AI investments. This is where MLOps (Machine Learning Operations) becomes a non‑negotiable requirement.
This article provides a structured guide to MLOps fundamentals, based on today’s reference ecosystem: MLflow as the machine learning lifecycle management platform, and Databricks as the enterprise environment that scales it. We explore how these tools address core challenges of traceability, reproducibility, and governance, and how their implementation lays the foundation for a mature AI operation.
The Structural Problem: Beyond the Notebook
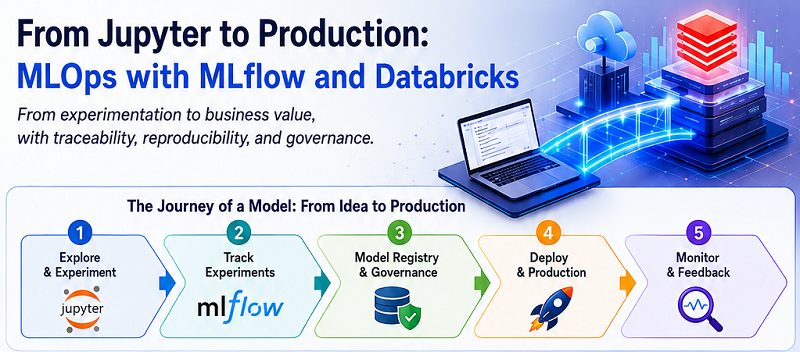
Traditional software development is deterministic. A function, given the same arguments, always returns the same result. Machine learning, by contrast, is inherently probabilistic. The same code and same data can produce different models. Add an intensive experimentation culturetesting dozens of hyperparameter combinations, architectures, and datasets and without proper discipline, operational chaos follows.
For any company aiming to scale AI initiatives, these questions must have immediate, clear answers:
- Exactly which version of the data and code produced this model?
- How do you systematically compare results across different experiments?
- Can you audit and reproduce a model from six months ago with complete fidelity?
- How do you govern the full model lifecycle: development, validation, deployment, monitoring, and eventual retirement?
Answering these requires a platform, not a collection of scripts.
MLflow: The Backbone of Your ML Operations
MLflow is an open‑source platform that has emerged as the de facto standard for managing the machine learning lifecycle. Its modular design addresses the four pillars of MLOps:
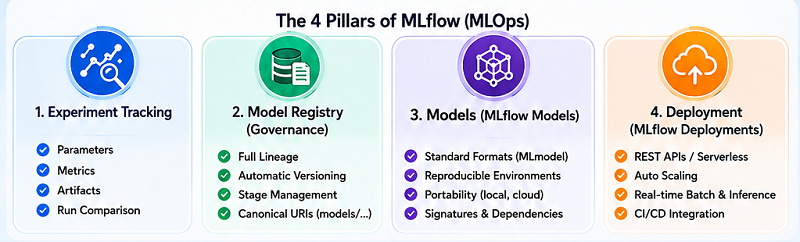
1. Experiment Tracking (MLflow Tracking)
Systematic tracking is the first step toward operational maturity. Each training run is recorded as a “run” that immutably captures:
- Parameters: Input variables (learning rate, max depth, etc.)
- Metrics: Quantitative performance indicators (accuracy, precision, loss)
- Artifacts: Generated products (serialized model, diagnostic plots, transformed data samples).
Architecturally, MLflow cleanly separates metadata storage (the Backend Store, typically a SQL database) from heavy artifact storage (the Artifact Store, such as AWS S3 or Azure Blob Storage). This separation is critical for scalability and allows distributed teams to share a central tracking server without saturating it with binary files.
2. The Model Registry: Governance and Lineage
Training models is only the beginning. Effective governance demands a centralized catalog that provides:
- Full lineage: Clear traceability from a production model back to the experiment, dataset, and code commit that created it.
- Automatic versioning: Each registered iteration becomes a new version, creating an unalterable history.
- Stage management: Models move through a defined workflow (Staging, Production, Archived), or use aliases like “champion” and “challenger” for A/B testing.
The Model URI concept (models:/<model_name>/<version-or-stage>) is particularly powerful because it decouples deployment from the model’s physical location, enabling clean, reproducible CI/CD pipelines
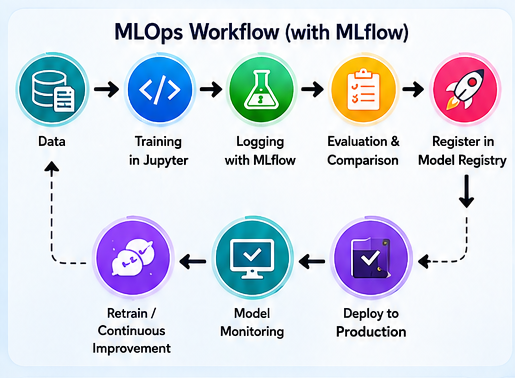
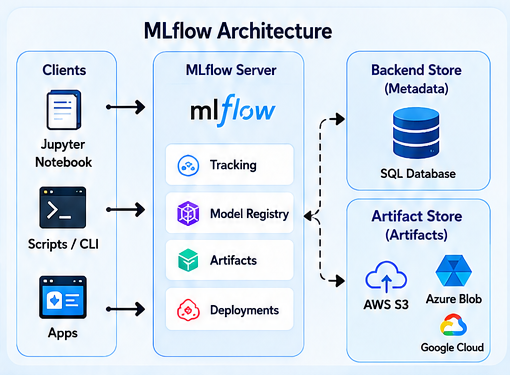
Technical Implementation: From Theory to Practice
Below are essential implementation patterns extracted from a real‑world MLflow workflow.
Environment Setup and Tracking Server
The first principle is isolation. A virtual environment per project is the foundation of reproducibility:
bash
python3.9 -m venv mlflow-env
source mlflow-env/bin/activate
pip install mlflow scikit-learn pandas matplotlibStart the tracking server locally for development; for production, configure remote backend and artifact stores:
bash
mlflow ui --host 0.0.0.0 --port 5000Structured Experiment Logging

The following pattern shows a complete run log, including parameters, metrics, and the resulting model:
python
import mlflow
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
mlflow.set_experiment("Iris_Experiment")
with mlflow.start_run(run_name="RandomForest_Base"):
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(
iris.data, iris.target, test_size=0.2, random_state=42
)
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=42)
model.fit(X_train, y_train)
# Log parameters
mlflow.log_param("n_estimators", 100)
mlflow.log_param("max_depth", 5)
# Log metrics
predictions = model.predict(X_test)
mlflow.log_metric("accuracy", accuracy_score(y_test, predictions))
# Log model as versioned artifact
mlflow.sklearn.log_model(model, "random_forest_model")Advanced Logging: Visualizations and Data
MLflow allows logging artifacts that go beyond numbers: loss curves, confusion matrices, and transformed data samples enriching traceability and debugging.
python
import matplotlib.pyplot as plt
# Log a diagnostic plot
plt.figure()
plt.plot(epochs, loss, marker='o')
plt.savefig("training_loss.png")
mlflow.log_artifact("training_loss.png")
plt.close()Automation with Auto‑logging
For supported frameworks like scikit‑learn, a single line enables automatic logging of parameters, metrics, and models—reducing boilerplate and the risk of human oversight:
python
mlflow.sklearn.autolog()The Model Registry in Action
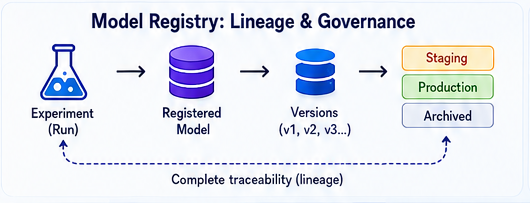
Once a candidate model is identified, register it formally:
python
mlflow.register_model(
f"runs:/<run_id>/random_forest_model",
"IrisClassifier"
)Then consume it from any environment using its canonical URI:
python
production_model = mlflow.pyfunc.load_model("models:/IrisClassifier/production")
predictions = production_model.predict(new_data)This pattern is the key to integrating model deployment into CI/CD pipelines.
Databricks: The Enterprise Environment for MLOps
If MLflow provides the engine, Databricks provides the enterprise platform that integrates it into a governed, collaborative ecosystem.
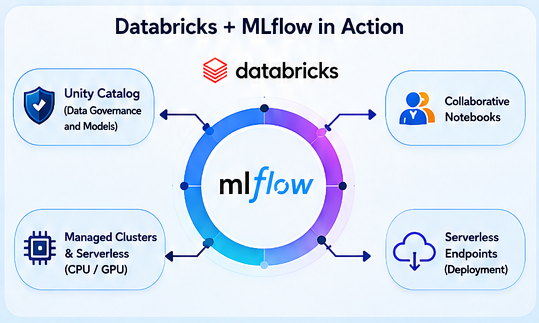
- Frictionless Collaboration: Experiments, notebooks, and models reside in a unified workspace. Unity Catalog delivers centralized data governance with fine‑grained, identity‑based access controls—applied to both data and models.
- Managed and Serverless Compute: Infrastructure management is fully abstracted. Clusters (with or without GPUs) are provisioned on demand, optimizing costs and eliminating operational overhead.
- Automated Tracking: Native integration with MLflow means tracking is transparently activated when training on Databricks notebooks.
- Nested Runs: For complex experiments like hyperparameter search, nested runs allow hierarchical organization, grouping multiple child runs under a parent run.
Advanced Case: Deploying Hugging Face Models with a Custom PyFunc
MLflow’s flexibility is fully realized when dealing with non‑tabular models. Consider deploying a Transformer model for sentiment analysis. The pattern is to encapsulate the model in a Python class that inherits from mlflow.pyfunc.PythonModel:
python
class TransformerModel(mlflow.pyfunc.PythonModel):
def load_context(self, context):
self.tokenizer = AutoTokenizer.from_pretrained(self.model_name)
self.model = AutoModelForSequenceClassification.from_pretrained(self.model_name)
def predict(self, context, model_input):
texts = model_input.iloc[:, 0].tolist()
inputs = self.tokenizer(texts, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
outputs = self.model(**inputs)
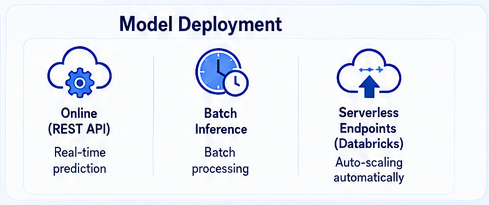
return pd.DataFrame(torch.softmax(outputs.logits, dim=-1).numpy())This custom model is packaged with its dependency environment and registered in Unity Catalog, ready to be served through a serverless REST endpoint. Critical concerns like cold‑start latency and horizontal scaling are handled by the platform.
Conclusion

Adopting MLOps is not a single event but a progressive evolution. From local experiment tracking to enterprise‑grade model governance in production, the tools and principles presented here form the foundation of a robust AI operation.
At OpsAnalytics, we understand this journey brings technical and organizational challenges. Our experience in DevOps and data platforms positions us to guide organizations in building the infrastructure, processes, and culture needed to make their models not just accurate, but reliable, scalable, and governable.
Is your organization ready to professionalize its machine learning operations? Contact us to discover how we can help you build the bridge between experimentation and tangible business value.

Leave a Reply